Kümeleme veya küme analizi, etiketlenmemiş veri kümesini gruplandıran bir makine öğrenme tekniğidir. Şu şekilde tanımlanabilir: 'Veri noktalarını benzer veri noktalarından oluşan farklı kümeler halinde gruplandırmanın bir yolu. Olası benzerliklere sahip nesneler, başka bir grupla benzerliği az olan veya hiç olmayan bir grupta kalır.'
Bunu, etiketlenmemiş veri kümesinde şekil, boyut, renk, davranış vb. gibi benzer kalıplar bularak yapar ve bunları bu benzer kalıpların varlığına ve yokluğuna göre böler.
O bir denetimsiz öğrenme Bu yöntem sayesinde algoritmaya herhangi bir denetim sağlanmaz ve etiketlenmemiş veri seti ile ilgilenir.
Bu kümeleme tekniği uygulandıktan sonra her kümeye veya gruba bir küme kimliği sağlanır. ML sistemi, büyük ve karmaşık veri kümelerinin işlenmesini basitleştirmek için bu kimliği kullanabilir.
Kümeleme tekniği yaygın olarak kullanılmaktadır. istatistiksel veri analizi.
Not: Kümeleme şuna benzer bir yerdedir: sınıflandırma algoritması ancak fark, kullandığımız veri kümesinin türüdür. Sınıflandırmada etiketli veri seti ile çalışıyoruz, kümelemede ise etiketlenmemiş veri seti ile çalışıyoruz.
Örnek : Kümeleme tekniğini gerçek hayattaki Mall örneğiyle anlayalım: Herhangi bir AVM'yi ziyaret ettiğimizde benzer kullanıma sahip eşyaların bir arada gruplandığını görebiliriz. Tişörtler bir bölümde, pantolonlar diğer bölümlerde olduğu gibi sebze reyonlarında da elmalar, muzlar, mangolar vb. ayrı bölümlerde gruplanıyor, böylece şeyleri kolayca bulabiliyoruz. Kümeleme tekniği de aynı şekilde çalışır. Kümelemenin diğer örnekleri, belgelerin konuya göre gruplandırılmasıdır.
Kümeleme tekniği çeşitli görevlerde yaygın olarak kullanılabilir. Bu tekniğin en yaygın kullanımlarından bazıları şunlardır:
- Pazar Segmentasyonu
- İstatistiksel veri analizi
- Sosyal ağ analizi
- Resim parçalama
- Anormallik tespiti vb.
Bu genel kullanımların dışında, Amazon Geçmiş ürün aramalarına göre öneriler sunmak için öneri sisteminde. netflix bu tekniği, izleme geçmişine göre film ve web dizilerini kullanıcılarına önermek için de kullanıyor.
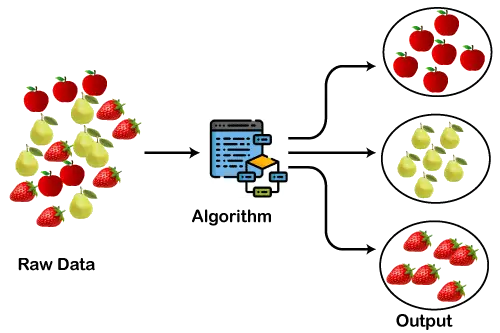
Aşağıdaki şemada kümeleme algoritmasının çalışması açıklanmaktadır. Farklı meyvelerin benzer özelliklere sahip çeşitli gruplara ayrıldığını görebiliriz.
Kümeleme Yöntemi Türleri
Kümeleme yöntemleri genel olarak aşağıdakilere ayrılmıştır: Sert kümeleme (veri noktası yalnızca bir gruba aittir) ve Yumuşak Kümeleme (veri noktaları başka bir gruba da ait olabilir). Ancak Kümelemenin başka çeşitli yaklaşımları da mevcuttur. Makine öğreniminde kullanılan ana kümeleme yöntemleri aşağıda verilmiştir:
Bölümleme Kümeleme
Verileri hiyerarşik olmayan gruplara ayıran bir kümeleme türüdür. Aynı zamanda şu şekilde de bilinir: merkeze dayalı yöntem . Bölümleme kümelemesinin en yaygın örneği, K-Means Kümeleme algoritması .
Bu türde, veri kümesi bir dizi k gruba bölünür; burada K, önceden tanımlanmış grupların sayısını tanımlamak için kullanılır. Küme merkezi, bir kümenin veri noktaları arasındaki mesafenin, başka bir küme merkezine kıyasla minimum olacak şekilde oluşturulur.

Yoğunluğa Dayalı Kümeleme
Yoğunluğa dayalı kümeleme yöntemi, yoğunluğu yüksek alanları kümeler halinde birleştirir ve yoğun bölge bağlanabildiği sürece keyfi şekilli dağılımlar oluşturulur. Bu algoritma bunu veri kümesindeki farklı kümeleri tanımlayarak yapar ve yüksek yoğunluklu alanları kümelere bağlar. Veri uzayındaki yoğun alanlar daha seyrek alanlarla birbirinden ayrılır.
Bu algoritmalar, veri kümesinin değişen yoğunluklara ve yüksek boyutlara sahip olması durumunda veri noktalarını kümelemede zorlukla karşılaşabilir.

Dağıtım Modeline Dayalı Kümeleme
Dağıtım modeli tabanlı kümeleme yönteminde veriler, bir veri kümesinin belirli bir dağılıma ait olma olasılığına göre bölünür. Gruplama bazı dağılımların ortak olduğu varsayılarak yapılır. Gauss dağılımı .
Bu türün örneği, Beklenti Maksimizasyon Kümeleme algoritması Gauss Karışım Modellerini (GMM) kullanır.

Hiyerarşik kümeleme
Oluşturulacak küme sayısının önceden belirlenmesine gerek olmadığından, bölümlenmiş kümelemeye alternatif olarak hiyerarşik kümeleme kullanılabilir. Bu teknikte veri kümesi kümelere bölünerek ağaç benzeri bir yapı oluşturulur. dendrogram . Ağacın doğru seviyede kesilmesiyle gözlemler veya herhangi bir sayıda küme seçilebilir. Bu yöntemin en yaygın örneği, Toplayıcı Hiyerarşik algoritma .

Bulanık Kümeleme
Bulanık kümeleme, bir veri nesnesinin birden fazla gruba veya kümeye ait olabileceği bir tür esnek yöntemdir. Her veri kümesi, bir kümedeki üyelik derecesine bağlı olan bir dizi üyelik katsayısına sahiptir. Bulanık C-ortalama algoritması bu tür kümelenmeye örnektir; bazen Bulanık k-ortalamalar algoritması olarak da bilinir.
huffman kodlama kodu
Kümeleme Algoritmaları
Kümeleme algoritmaları yukarıda açıklanan modellerine göre ayrılabilir. Yayınlanmış farklı türde kümeleme algoritmaları vardır, ancak yalnızca birkaçı yaygın olarak kullanılmaktadır. Kümeleme algoritması kullandığımız veri türüne dayanmaktadır. Örneğin, bazı algoritmaların verilen veri kümesindeki küme sayısını tahmin etmesi gerekirken, bazılarının ise veri kümesinin gözlemleri arasındaki minimum mesafeyi bulması gerekir.
Burada esas olarak makine öğreniminde yaygın olarak kullanılan popüler Kümeleme algoritmalarını tartışıyoruz:
Kümeleme Uygulamaları
Aşağıda Makine Öğreniminde kümeleme tekniğinin yaygın olarak bilinen bazı uygulamaları verilmiştir: